BigQuery
https://cloud.google.com/bigquery
![]()
![]()
![]()
Install
Install Ibis and dependencies for the BigQuery backend:
Install with the bigquery extra:
pip install 'ibis-framework[bigquery]'And connect:
import ibis
con = ibis.bigquery.connect()- 1
- Adjust connection parameters as needed.
Install for BigQuery:
conda install -c conda-forge ibis-bigqueryAnd connect:
import ibis
con = ibis.bigquery.connect()- 1
- Adjust connection parameters as needed.
Install for BigQuery:
mamba install -c conda-forge ibis-bigqueryAnd connect:
import ibis
con = ibis.bigquery.connect()- 1
- Adjust connection parameters as needed.
Connect
ibis.bigquery.connect
con = ibis.bigquery.connect(
project_id="ibis-bq-project",
dataset_id="testing",
)ibis.bigquery.connect is a thin wrapper around ibis.backends.bigquery.Backend.do_connect.
Connection Parameters
do_connect
do_connect(self, project_id=None, dataset_id='', credentials=None, application_name=None, auth_local_webserver=True, auth_external_data=False, auth_cache='default', partition_column='PARTITIONTIME', client=None, storage_client=None, location=None, generate_job_id_prefix=None)
Create a Backend for use with Ibis.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| project_id | str | None | A BigQuery project id. | None |
| dataset_id | str | A dataset id that lives inside of the project indicated by project_id. |
'' |
| credentials | google.auth.credentials.Credentials | None | Optional credentials. | None |
| application_name | str | None | A string identifying your application to Google API endpoints. | None |
| auth_local_webserver | bool | Use a local webserver for the user authentication. Binds a webserver to an open port on localhost between 8080 and 8089, inclusive, to receive authentication token. If not set, defaults to False, which requests a token via the console. | True |
| auth_external_data | bool | Authenticate using additional scopes required to query external data sources <https://cloud.google.com/bigquery/external-data-sources>_, such as Google Sheets, files in Google Cloud Storage, or files in Google Drive. If not set, defaults to False, which requests the default BigQuery scopes. |
False |
| auth_cache | str | Selects the behavior of the credentials cache. 'default'`` Reads credentials from disk if available, otherwise authenticates and caches credentials to disk.‘reauth’Authenticates and caches credentials to disk. `'none' Authenticates and does not cache credentials. Defaults to 'default'. |
'default' |
| partition_column | str | None | Identifier to use instead of default _PARTITIONTIME partition column. Defaults to 'PARTITIONTIME'. |
'PARTITIONTIME' |
| client | bq.Client | None | A Client from the google.cloud.bigquery package. If not set, one is created using the project_id and credentials. |
None |
| storage_client | bqstorage.BigQueryReadClient | None | A BigQueryReadClient from the google.cloud.bigquery_storage_v1 package. If not set, one is created using the project_id and credentials. |
None |
| location | str | None | Default location for BigQuery objects. | None |
| generate_job_id_prefix | Callable[[], str | None] | None | Optional callable that generates a bigquery job ID prefix. If specified, for any query job, jobs will always be created rather than optionally created by BigQuery’s Client.query_and_wait. |
None |
Returns
| Name | Type | Description |
|---|---|---|
| Backend | An instance of the BigQuery backend. |
ibis.connect URL format
In addition to ibis.bigquery.connect, you can also connect to BigQuery by passing a properly-formatted BigQuery connection URL to ibis.connect:
con = ibis.connect(f"bigquery://{project_id}/{dataset_id}")This assumes you have already authenticated via the gcloud CLI.
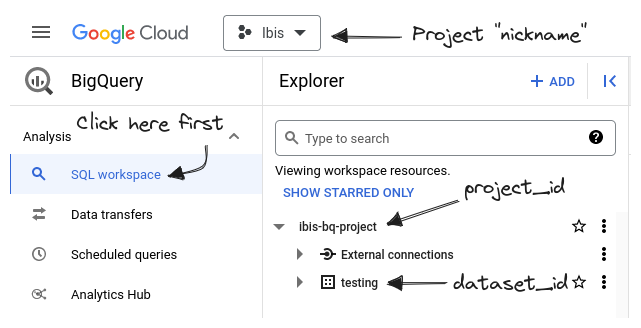
Finding your project_id and dataset_id
Log in to the Google Cloud Console to see which project_ids and dataset_ids are available to use.
BigQuery Authentication
The simplest way to authenticate with the BigQuery backend is to use Google’s gcloud CLI tool.
Once you have gcloud installed, you can authenticate to BigQuery (and other Google Cloud services) by running
gcloud auth login --update-adcYou will also likely want to configure a default project:
gcloud config set core/project <project_id>For any authentication problems, or information on other ways of authenticating, see the gcloud CLI authorization guide.
bigquery.Backend
compile
compile(self, expr, /, *, limit=None, params=None, pretty=True, **kwargs)
Compile an expression.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Expr | An ibis expression to compile. | required |
| limit | str | int | None | An integer to effect a specific row limit. A value of None means no limit. The default is in ibis/config.py. |
None |
| params | Mapping[ir.Expr, Any] | None | Mapping of scalar parameter expressions to value. | None |
| pretty | bool | If True, the resulting SQL will be formatted for human readability |
True |
| kwargs | Any | Additional keyword arguments | {} |
connect
connect(self, *args, **kwargs)
Connect to the database.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| *args | Mandatory connection parameters, see the docstring of do_connect for details. |
() |
|
| **kwargs | Extra connection parameters, see the docstring of do_connect for details. |
{} |
Notes
This creates a new backend instance with saved args and kwargs, then calls reconnect and finally returns the newly created and connected backend instance.
Returns
| Name | Type | Description |
|---|---|---|
| BaseBackend | An instance of the backend |
create_database
create_database(self, name, /, *, catalog=None, force=False, collate=None, **options)
Create a database named name in catalog.
schema to refer to database hierarchy.
A collection of table is referred to as a database. A collection of database is referred to as a catalog.
These terms are mapped onto the corresponding features in each backend (where available), regardless of the terminology the backend uses.
See the Table Hierarchy Concepts Guide for more info.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| name | str | Name of the database to create. | required |
| catalog | str | None | Name of the catalog in which to create the database. If None, the current catalog is used. |
None |
| force | bool | If False, an exception is raised if the database exists. |
False |
create_table
create_table(self, name, /, obj=None, *, schema=None, database=None, temp=False, overwrite=False, default_collate=None, partition_by=None, cluster_by=None, options=None)
Create a table in BigQuery.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| name | str | Name of the table to create | required |
| obj | ir.Table | pd.DataFrame | pa.Table | pl.DataFrame | pl.LazyFrame | None | The data with which to populate the table; optional, but one of obj or schema must be specified |
None |
| schema | sch.IntoSchema | None | The schema of the table to create; optional, but one of obj or schema must be specified |
None |
| database | str | None | The BigQuery dataset in which to create the table; optional | None |
| temp | bool | Whether the table is temporary | False |
| overwrite | bool | If True, replace the table if it already exists, otherwise fail if the table exists |
False |
| default_collate | str | None | Default collation for string columns. See BigQuery’s documentation for more details: https://cloud.google.com/bigquery/docs/reference/standard-sql/collation-concepts | None |
| partition_by | str | None | Partition the table by the given expression. See BigQuery’s documentation for more details: https://cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language#partition_expression | None |
| cluster_by | Iterable[str] | None | List of columns to cluster the table by. See BigQuery’s documentation for more details: https://cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language#clustering_column_list | None |
| options | Mapping[str, Any] | None | BigQuery-specific table options; see the BigQuery documentation for details: https://cloud.google.com/bigquery/docs/reference/standard-sql/data-definition-language#table_option_list | None |
Returns
| Name | Type | Description |
|---|---|---|
| Table | The table that was just created |
create_view
create_view(self, name, /, obj, *, database=None, overwrite=False)
Create a view from an Ibis expression.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| name | str | The name of the view to create. | required |
| obj | ir.Table | The Ibis expression to create the view from. | required |
| database | str | None | The database that the view should be created in. | None |
| overwrite | bool | If True, replace an existing view with the same name. |
False |
Returns
| Name | Type | Description |
|---|---|---|
| ir.Table | A table expression representing the view. |
disconnect
disconnect(self)
Disconnect from the backend.
drop_database
drop_database(self, name, /, *, catalog=None, force=False, cascade=False)
Drop a BigQuery dataset.
drop_table
drop_table(self, name, /, *, database=None, force=False)
Drop a table from the backend.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| name | str | The name of the table to drop | required |
| database | tuple[str, str] | str | None | The database that the table is located in. | None |
| force | bool | If True, do not raise an error if the table does not exist. |
False |
drop_view
drop_view(self, name, /, *, database=None, force=False)
Drop a view from the backend.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| name | str | The name of the view to drop. | required |
| database | str | None | The database that the view is located in. | None |
| force | bool | If True, do not raise an error if the view does not exist. |
False |
execute
execute(self, expr, /, *, params=None, limit=None, query_job_config=None, **kwargs)
Compile and execute the given Ibis expression.
Compile and execute Ibis expression using this backend client interface, returning results in-memory in the appropriate object type
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Expr | Ibis expression to execute | required |
| limit | int | str | None | Retrieve at most this number of values/rows. Overrides any limit already set on the expression. | None |
| params | Mapping[ir.Scalar, Any] | None | Query parameters | None |
| query_job_config | bq.QueryJobConfig | None | QueryJobConfig, the values in the params argument take precedence over the ones in this object |
None |
| kwargs | Any | Extra arguments specific to the backend | {} |
Returns
| Name | Type | Description |
|---|---|---|
| pd.DataFrame | pd.Series | scalar | Output from execution |
from_connection
from_connection(cls, client, /, *, partition_column='PARTITIONTIME', storage_client=None, dataset_id='')
Create a BigQuery Backend from an existing Client.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| client | bq.Client | A Client from the google.cloud.bigquery package. |
required |
| partition_column | str | None | Identifier to use instead of default _PARTITIONTIME partition column. Defaults to 'PARTITIONTIME'. |
'PARTITIONTIME' |
| storage_client | bqstorage.BigQueryReadClient | None | A BigQueryReadClient from the google.cloud.bigquery_storage_v1 package. |
None |
| dataset_id | str | A dataset id that lives inside of the project attached to client. |
'' |
get_schema
get_schema(self, name, *, catalog=None, database=None)
has_operation
has_operation(cls, operation, /)
Return whether the backend supports the given operation.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| operation | type[ops.Value] | Operation type, a Python class object. | required |
insert
insert(self, name, /, obj, *, database=None, overwrite=False)
Insert data into a table.
schema to refer to database hierarchy.
A collection of table is referred to as a database. A collection of database is referred to as a catalog.
These terms are mapped onto the corresponding features in each backend (where available), regardless of whether the backend itself uses the same terminology.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| name | str | The name of the table to which data needs will be inserted. | required |
| obj | ir.Table | IntoMemtable | The source data or expression to insert. | required |
| database | str | None | Name of the attached database that the table is located in. | None |
| overwrite | bool | If True then replace existing contents of table. |
False |
list_databases
list_databases(self, *, like=None, catalog=None)
List existing databases in the current connection.
schema to refer to database hierarchy.
A collection of table is referred to as a database. A collection of database is referred to as a catalog.
These terms are mapped onto the corresponding features in each backend (where available), regardless of the terminology the backend uses.
See the Table Hierarchy Concepts Guide for more info.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| like | str | None | A pattern in Python’s regex format to filter returned database names. | None |
| catalog | str | None | The catalog to list databases from. If None, the current catalog is searched. |
None |
Returns
| Name | Type | Description |
|---|---|---|
| list[str] | The database names that exist in the current connection, that match the like pattern if provided. |
list_tables
list_tables(self, *, like=None, database=None)
The table names that match like in the given database.
For some backends, the tables may be files in a directory, or other equivalent entities in a SQL database.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| like | str | None | A pattern in Python’s regex format. | None |
| database | tuple[str, str] | str | None | The database, or (catalog, database) from which to list tables. For backends that support a single-level table hierarchy, you can pass in a string like "bar". For backends that support multi-level table hierarchies, you can pass in a dotted string path like "catalog.database" or a tuple of strings like ("catalog", "database"). If not provided, the current database (and catalog, if applicable for this backend) is used. See the Table Hierarchy Concepts Guide for more info. |
None |
Returns
| Name | Type | Description |
|---|---|---|
| list[str] | The list of the table names that match the pattern like. |
Examples
This example uses the DuckDB backend, but the list_tables API works the same for other backends.
>>> import ibis
>>> con = ibis.duckdb.connect()
>>> foo = con.create_table("foo", schema=ibis.schema(dict(a="int")))
>>> con.list_tables()
['foo']
>>> bar = con.create_view("bar", foo)
>>> con.list_tables()
['bar', 'foo']
>>> con.create_database("my_database")
>>> con.list_tables(database="my_database")
[]
>>> con.raw_sql("CREATE TABLE my_database.baz (a INTEGER)")
<duckdb.duckdb.DuckDBPyConnection object at 0x...>
>>> con.list_tables(database="my_database")
['baz']raw_sql
raw_sql(self, query, params=None, query_job_config=None)
read_csv
read_csv(self, path, /, *, table_name=None, **kwargs)
Read CSV data into a BigQuery table.
If the table already exists, it will be dropped before loading.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| path | str | Path | Path to a CSV file on GCS or the local filesystem. Globs are supported. | required |
| table_name | str | None | Optional table name | None |
| kwargs | Any | Additional keyword arguments passed to google.cloud.bigquery.LoadJobConfig. |
{} |
Returns
| Name | Type | Description |
|---|---|---|
| Table | An Ibis table expression |
read_delta
read_delta(self, path, /, *, table_name=None, **kwargs)
Register a Delta Lake table in the current database.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| path | str | Path | The data source. Must be a directory containing a Delta Lake table. | required |
| table_name | str | None | An optional name to use for the created table. This defaults to a sequentially generated name. | None |
| **kwargs | Any | Additional keyword arguments passed to the underlying backend or library. | {} |
Returns
| Name | Type | Description |
|---|---|---|
| ir.Table | The just-registered table. |
read_json
read_json(self, path, /, *, table_name=None, **kwargs)
Read newline-delimited JSON data into a BigQuery table.
If the table already exists, it will be dropped before loading.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| path | str | Path | Path to a newline-delimited JSON file on GCS or the local filesystem. Globs are supported. | required |
| table_name | str | None | Optional table name | None |
| kwargs | Any | Additional keyword arguments passed to google.cloud.bigquery.LoadJobConfig. |
{} |
Returns
| Name | Type | Description |
|---|---|---|
| Table | An Ibis table expression |
read_parquet
read_parquet(self, path, /, *, table_name=None, **kwargs)
Read Parquet data into a BigQuery table.
If the table already exists, it will be dropped before loading.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| path | str | Path | Path to a Parquet file on GCS or the local filesystem. Globs are supported. | required |
| table_name | str | None | Optional table name | None |
| kwargs | Any | Additional keyword arguments passed to google.cloud.bigquery.LoadJobConfig. |
{} |
Returns
| Name | Type | Description |
|---|---|---|
| Table | An Ibis table expression |
reconnect
reconnect(self)
Reconnect to the database already configured with connect.
register_options
register_options(cls)
Register custom backend options.
rename_table
rename_table(self, old_name, new_name)
Rename an existing table.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| old_name | str | The old name of the table. | required |
| new_name | str | The new name of the table. | required |
set_database
set_database(self, name, /)
sql
sql(self, query, /, *, schema=None, dialect=None)
Create an Ibis table expression from a SQL query.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| query | str | A SQL query string | required |
| schema | IntoSchema | None | The schema of the query. If not provided, Ibis will try to infer the schema of the query. | None |
| dialect | str | None | The SQL dialect of the query. If not provided, the backend’s dialect is assumed. This argument can be useful when the query is written in a different dialect from the backend. | None |
Returns
| Name | Type | Description |
|---|---|---|
| ir.Table | The table expression representing the query |
table
table(self, name, /, *, database=None)
to_csv
to_csv(self, expr, /, path, *, params=None, **kwargs)
Write the results of executing the given expression to a CSV file.
This method is eager and will execute the associated expression immediately.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Table | The ibis expression to execute and persist to CSV. | required |
| path | str | Path | The data source. A string or Path to the CSV file. | required |
| params | Mapping[ir.Scalar, Any] | None | Mapping of scalar parameter expressions to value. | None |
| kwargs | Any | Additional keyword arguments passed to pyarrow.csv.CSVWriter | {} |
| https | required |
to_delta
to_delta(self, expr, /, path, *, params=None, **kwargs)
Write the results of executing the given expression to a Delta Lake table.
This method is eager and will execute the associated expression immediately.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Table | The ibis expression to execute and persist to Delta Lake table. | required |
| path | str | Path | The data source. A string or Path to the Delta Lake table. | required |
| params | Mapping[ir.Scalar, Any] | None | Mapping of scalar parameter expressions to value. | None |
| kwargs | Any | Additional keyword arguments passed to deltalake.writer.write_deltalake method | {} |
to_json
to_json(self, expr, /, path, **kwargs)
Write the results of expr to a json file of [{column -> value}, …] objects.
This method is eager and will execute the associated expression immediately.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Table | The ibis expression to execute and persist to Delta Lake table. | required |
| path | str | Path | The data source. A string or Path to the Delta Lake table. | required |
| kwargs | Any | Additional, backend-specifc keyword arguments. | {} |
to_pandas
to_pandas(self, expr, /, *, params=None, limit=None, **kwargs)
Execute an Ibis expression and return a pandas DataFrame, Series, or scalar.
This method is a wrapper around execute.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Expr | Ibis expression to execute. | required |
| params | Mapping[ir.Scalar, Any] | None | Mapping of scalar parameter expressions to value. | None |
| limit | int | str | None | An integer to effect a specific row limit. A value of None means no limit. The default is in ibis/config.py. |
None |
| kwargs | Any | Keyword arguments | {} |
to_pandas_batches
to_pandas_batches(self, expr, /, *, params=None, limit=None, chunk_size=1000000, **kwargs)
Execute an Ibis expression and return an iterator of pandas DataFrames.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Expr | Ibis expression to execute. | required |
| params | Mapping[ir.Scalar, Any] | None | Mapping of scalar parameter expressions to value. | None |
| limit | int | str | None | An integer to effect a specific row limit. A value of None means no limit. The default is in ibis/config.py. |
None |
| chunk_size | int | Maximum number of rows in each returned DataFrame batch. This may have no effect depending on the backend. |
1000000 |
| kwargs | Any | Keyword arguments | {} |
Returns
| Name | Type | Description |
|---|---|---|
| Iterator[pd.DataFrame] | An iterator of pandas DataFrames. |
to_parquet
to_parquet(self, expr, /, path, *, params=None, **kwargs)
Write the results of executing the given expression to a parquet file.
This method is eager and will execute the associated expression immediately.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Table | The ibis expression to execute and persist to parquet. | required |
| path | str | Path | The data source. A string or Path to the parquet file. | required |
| params | Mapping[ir.Scalar, Any] | None | Mapping of scalar parameter expressions to value. | None |
| **kwargs | Any | Additional keyword arguments passed to pyarrow.parquet.ParquetWriter | {} |
| https | required |
to_parquet_dir
to_parquet_dir(self, expr, /, directory, *, params=None, **kwargs)
Write the results of executing the given expression to a parquet file in a directory.
This method is eager and will execute the associated expression immediately.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Table | The ibis expression to execute and persist to parquet. | required |
| directory | str | Path | The data source. A string or Path to the directory where the parquet file will be written. | required |
| params | Mapping[ir.Scalar, Any] | None | Mapping of scalar parameter expressions to value. | None |
| **kwargs | Any | Additional keyword arguments passed to pyarrow.dataset.write_dataset | {} |
| https | required |
to_polars
to_polars(self, expr, /, *, params=None, limit=None, **kwargs)
Execute expression and return results in as a polars DataFrame.
This method is eager and will execute the associated expression immediately.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Expr | Ibis expression to export to polars. | required |
| params | Mapping[ir.Scalar, Any] | None | Mapping of scalar parameter expressions to value. | None |
| limit | int | str | None | An integer to effect a specific row limit. A value of None means no limit. The default is in ibis/config.py. |
None |
| kwargs | Any | Keyword arguments | {} |
Returns
| Name | Type | Description |
|---|---|---|
| dataframe | A polars DataFrame holding the results of the executed expression. |
to_pyarrow
to_pyarrow(self, expr, /, *, params=None, limit=None, query_job_config=None, **kwargs)
Execute expression to a pyarrow object.
This method is eager and will execute the associated expression immediately.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Expr | Ibis expression to export to pyarrow | required |
| params | Mapping[ir.Scalar, Any] | None | Mapping of scalar parameter expressions to value. | None |
| limit | int | str | None | An integer to effect a specific row limit. A value of None means no limit. The default is in ibis/config.py. |
None |
| kwargs | Any | Keyword arguments | {} |
Returns
| Name | Type | Description |
|---|---|---|
| result | If the passed expression is a Table, a pyarrow table is returned. If the passed expression is a Column, a pyarrow array is returned. If the passed expression is a Scalar, a pyarrow scalar is returned. |
to_pyarrow_batches
to_pyarrow_batches(self, expr, /, *, params=None, limit=None, chunk_size=1000000, query_job_config=None, **kwargs)
Execute expression and return an iterator of PyArrow record batches.
This method is eager and will execute the associated expression immediately.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Expr | Ibis expression to export to pyarrow | required |
| limit | int | str | None | An integer to effect a specific row limit. A value of None means “no limit”. The default is in ibis/config.py. |
None |
| params | Mapping[ir.Scalar, Any] | None | Mapping of scalar parameter expressions to value. | None |
| chunk_size | int | Maximum number of rows in each returned record batch. | 1000000 |
Returns
| Name | Type | Description |
|---|---|---|
| RecordBatchReader | Collection of pyarrow RecordBatchs. |
to_torch
to_torch(self, expr, /, *, params=None, limit=None, **kwargs)
Execute an expression and return results as a dictionary of torch tensors.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| expr | ir.Expr | Ibis expression to execute. | required |
| params | Mapping[ir.Scalar, Any] | None | Parameters to substitute into the expression. | None |
| limit | int | str | None | An integer to effect a specific row limit. A value of None means no limit. |
None |
| kwargs | Any | Keyword arguments passed into the backend’s to_torch implementation. |
{} |
Returns
| Name | Type | Description |
|---|---|---|
| dict[str, torch.Tensor] | A dictionary of torch tensors, keyed by column name. |
truncate_table
truncate_table(self, name, /, *, database=None)
Delete all rows from a table.
schema to refer to database hierarchy.
A collection of table is referred to as a database. A collection of database is referred to as a catalog.
These terms are mapped onto the corresponding features in each backend (where available), regardless of whether the backend itself uses the same terminology.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| name | str | Table name | required |
| database | str | tuple[str, str] | None | Name of the attached database that the table is located in. For backends that support multi-level table hierarchies, you can pass in a dotted string path like "catalog.database" or a tuple of strings like ("catalog", "database"). |
None |
upsert
upsert(self, name, /, obj, on, *, database=None)
Upsert data into a table.
schema to refer to database hierarchy.
A collection of table is referred to as a database. A collection of database is referred to as a catalog.
These terms are mapped onto the corresponding features in each backend (where available), regardless of whether the backend itself uses the same terminology.
Parameters
| Name | Type | Description | Default |
|---|---|---|---|
| name | str | The name of the table to which data will be upserted | required |
| obj | ir.Table | IntoMemtable | The source data or expression to upsert | required |
| on | str | Column name to join on | required |
| database | str | None | Name of the attached database that the table is located in. For backends that support multi-level table hierarchies, you can pass in a dotted string path like "catalog.database" or a tuple of strings like ("catalog", "database"). |
None |