┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ bill_length_mm ┃ bill_depth_mm ┃ flipper_length_mm ┃ body_mass_g ┃ sex ┃ year ┃ ┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━┩ │ string │ string │ float64 │ float64 │ int64 │ int64 │ string │ int64 │ ├─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼───────┤ │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181 │ 3750 │ male │ 2007 │ │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186 │ 3800 │ female │ 2007 │ │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195 │ 3250 │ female │ 2007 │ │ Adelie │ Torgersen │ NULL │ NULL │ NULL │ NULL │ NULL │ 2007 │ │ Adelie │ Torgersen │ 36.7 │ 19.3 │ 193 │ 3450 │ female │ 2007 │ │ Adelie │ Torgersen │ 39.3 │ 20.6 │ 190 │ 3650 │ male │ 2007 │ │ Adelie │ Torgersen │ 38.9 │ 17.8 │ 181 │ 3625 │ female │ 2007 │ │ Adelie │ Torgersen │ 39.2 │ 19.6 │ 195 │ 4675 │ male │ 2007 │ │ Adelie │ Torgersen │ 34.1 │ 18.1 │ 193 │ 3475 │ NULL │ 2007 │ │ Adelie │ Torgersen │ 42.0 │ 20.2 │ 190 │ 4250 │ NULL │ 2007 │ │ … │ … │ … │ … │ … │ … │ … │ … │ └─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴───────┘
Ibis @ LinkedIn
Portable Python DataFrames
2024-04-24
SQL
SELECT
"t0"."species",
"t0"."island",
"t0"."bill_length_mm" - AVG("t0"."bill_length_mm") OVER (
PARTITION BY "t0"."species"
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS "bill_length_mm",
"t0"."bill_depth_mm" - AVG("t0"."bill_depth_mm") OVER (
PARTITION BY "t0"."species"
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS "bill_depth_mm",
"t0"."flipper_length_mm" - AVG("t0"."flipper_length_mm") OVER (
PARTITION BY "t0"."species"
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS "flipper_length_mm",
"t0"."body_mass_g" - AVG("t0"."body_mass_g") OVER (
PARTITION BY "t0"."species"
ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING
) AS "body_mass_g",
"t0"."sex",
"t0"."year"
FROM "penguins" AS "t0"
LIMIT 5
The legal dept requires this slide

Ibis bridges the gap.
Components: expressions

Components: compiler
graph BT classDef white color:white; %% graph definition DatabaseTable --> species DatabaseTable --> bill_length_mm bill_length_mm --> Mean species --> Aggregate Mean --> Aggregate %% style class DatabaseTable white; class species white; class bill_length_mm white; class Mean white; class Aggregate white;
graph BT classDef white color:white; DatabaseTable2[DatabaseTable] --> species2[species] species2 --> bill_length_mm2[bill_length_mm] bill_length_mm2 --> Mean2[Mean] Mean2 --> Aggregate2[Aggregate] %% style class DatabaseTable2 white; class species2 white; class bill_length_mm2 white; class Mean2 white; class Aggregate2 white;
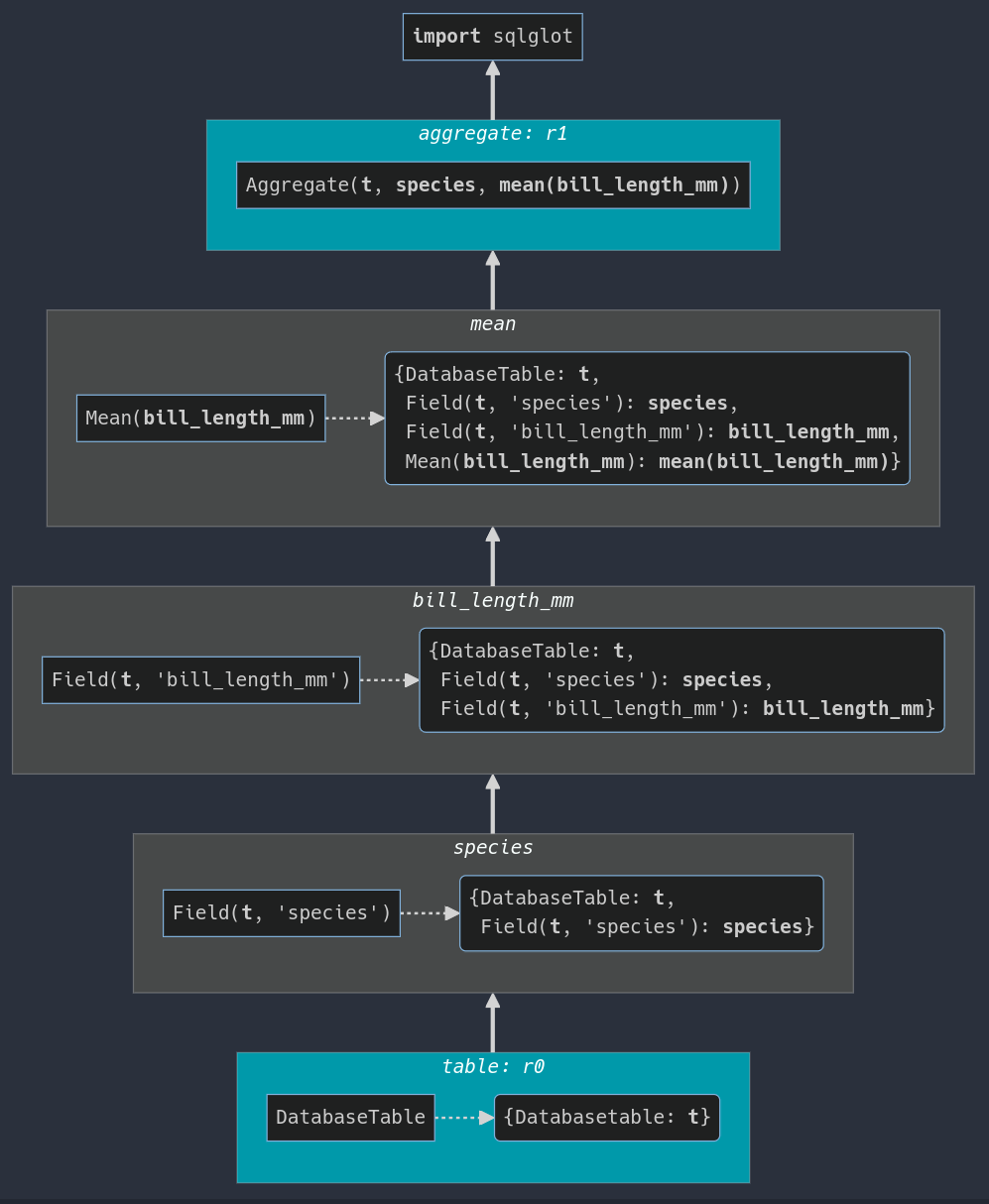

Components: compiler
Components: drivers

Drivers
- We have SQL at this point
- Send to DB via DBAPI:
cursor.execute(ibis_generated_sql) - (Heavily) massage the output
Growth of streaming
- Over 70% of Fortune 500 companies have adopted Kafka
- 54% of Databricks’ customers are using Spark Structured Streaming
- The stream processing market is expected to grow at a compound annual growth rate (CAGR) of 21.5% from 2022 to 2028 (IDC)
Batch and streaming
graph LR
subgraph " "
direction LR
A[data] --> B[batch processing] & C[stream processing] --> D[downstream]
end


Stream-batch unification
![]()
Towards composable data systems