Designing Interfaces is hard
Gil Forsyth
2024-09-17
Who?
Me
- Gil Forsyth
- Ibis project
- Xonsh
- Voltron Data
- Recovering academic
Link to slides

Show of hands
Who here is a…
- Data analyst / Data scientist?
- Data engineer?
- Software engineer?
- ML something-something?
Who here uses…
- 🦀Rust?
- 🐍Python?
- 🤖SQL?
- 🇷R?
- 🧨KDB+ Q?
So you want to design a Python Dataframe API?
Python🐍/pandas🐼 terminology or SQL🤖 terminology?
order_byororderbyorsortorsort_byorsortby?group_byorgroupbyorpartitionorpartition_byorpartitionby?
🙏please only choose one🙏
when in doubt, copy dplyr
Python🐍/pandas🐼 semantics or SQL🤖 semantics?
- 0-indexing or 1-indexing?
- Do
rpadandlpadalsotrim? - Is implicit ordering guaranteed everywhere?
- Are multi-indexes a good idea? (No)
So you want to design a SQL dialect?
(SQL) Questions with no (single) answer
- Does a week start on Sunday or Monday?
- Are the days of a week 0-indexed or 1-indexed?
- Do nulls sort ascending, or descending, or always first, or always last?
- Given a function to compute \(log_b(x)\), is the function signature:
log(b, x)?log(x, b)?
SQL ain’t standard
Which is why, when you ask: How many Star Wars characters have 'Darth' in their name?
SQL ain’t standard
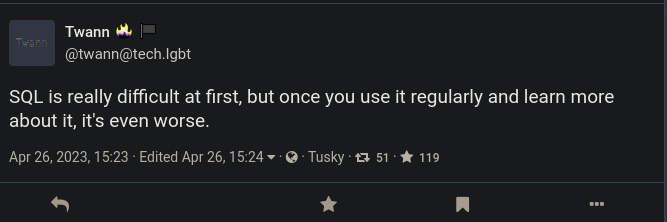
Wait, what is this talk about?
We built a dataframe interface!
Ibis
- Open-source (Apache 2.0)
- Pure Python
- DataFrame interface
- Pretty cool
- Independently governed
- Started by Wes McKinney
![]()
(Some) Answers to the DataFrame questions




Because remember what happened to SQL?
(It was bad)
We’re trying to stop this 1:
And yes…

Ibis is only an interface
- Not an engine
- We don’t compute anything
- We work with a lot of engines
Demo Time
Why use DataFusion?
- It’s fast
- It’s flexible
- Interface agnostic (SQL, Substrait, Dataframe API)
You should choose the engine that suits your problem.
Why use Ibis?
- It’s flexible
- It’s a pretty good API (no really!)
- Engine agnostic
You should choose the interface that suits your problem.1
The interface is not the engine is not the interface
- Don’t let the engine dictate the interface
- Don’t let the interface dictate the engine
Try it out
pip install 'ibis-framework[datafusion]'conda install -c conda-forge ibis-datafusionQuestions
Shouldn’t we all copy the pandas API?
No.
pandas is a good tool, provided:
- your data fit in memory (implicitly ordered)
- you want eager execution
What other backends does Ibis support?
- BigQuery
- ClickHouse
- DataFusion
- Druid
- DuckDB
- Exasol
- Flink
- Impala
- MSSQL
- MySQL
- Oracle
- Polars
- Postgres
- Spark
- Risingwave
- Snowflake
- SQLite
- Trino
Should I use Ibis instead of X?
Nope. You should use Ibis with X.
Demo code (for reference)
import ibis
con = ibis.datafusion.connect()
ibis.set_backend(con)
ratings = ibis.examples.imdb_title_ratings.fetch()
basics = ibis.examples.imdb_title_basics.fetch()
basics.filter(basics.titleType == "movie", basics.isAdult == 0).join(
ratings, "tconst"
).filter(ratings.numVotes > 100_000).order_by(ratings.averageRating.desc()).select(
"primaryTitle", "averageRating"
).limit(10)import glob
import os
import pandas as pd
def main():
df = pd.read_parquet(
min(glob.glob("/home/gil/databog/parquet/pypi/*.parquet"), key=os.path.getsize),
columns=["path", "uploaded_on", "project_name"],
)
df = df[
df.path.str.contains(
r"\.(?:asm|c|cc|cpp|cxx|h|hpp|rs|[Ff][0-9]{0,2}(?:or)?|go)$"
)
& ~df.path.str.contains(r"(?:(?:^|/)test(?:|s|ing)|/site-packages/)")
]
return (
df.assign(
month=df.uploaded_on.dt.to_period("M").dt.to_timestamp(),
ext=df.path.str.extract(r"\.([a-z0-9]+)$", 0)
.iloc[:, 0]
.str.replace(r"cxx|cpp|cc|c|hpp|h", "C/C++", regex=True)
.str.replace("^f.*$", "Fortran", regex=True)
.str.replace("rs", "Rust")
.str.replace("go", "Go")
.str.replace("asm", "Assembly"),
)
.groupby(["month", "ext"])
.project_name.nunique()
.rename("project_count")
.reset_index()
.sort_values(["month", "project_count"], ascending=False)
)import glob
import os.path
import ibis
from ibis import _
con = ibis.datafusion.connect()
expr = (
con.read_parquet(
min(glob.glob("/home/gil/databog/parquet/pypi/*.parquet"), key=os.path.getsize)
)
.filter(
[
_.path.re_search(
r"\.(asm|c|cc|cpp|cxx|h|hpp|rs|[Ff][0-9]{0,2}(?:or)?|go)$"
),
~_.path.re_search(r"(^|/)test(|s|ing)"),
~_.path.contains("/site-packages/"),
]
)
.group_by(
month=_.uploaded_on.truncate("M"),
ext=_.path.re_extract(r"\.([a-z0-9]+)$", 1)
.re_replace(r"cxx|cpp|cc|c|hpp|h", "C/C++")
.re_replace("^f.*$", "Fortran")
.replace("rs", "Rust")
.replace("go", "Go")
.replace("asm", "Assembly")
.nullif(""),
)
.aggregate(project_count=_.project_name.nunique())
.drop_null("ext")
.order_by([_.month.desc(), _.project_count.desc()])
)import ibis
from ibis import _
con = ibis.datafusion.connect()
expr = (
con.read_parquet("/home/gil/databog/parquet/pypi/*.parquet")
.filter(
[
_.path.re_search(
r"\.(asm|c|cc|cpp|cxx|h|hpp|rs|[Ff][0-9]{0,2}(?:or)?|go)$"
),
~_.path.re_search(r"(^|/)test(|s|ing)"),
~_.path.contains("/site-packages/"),
]
)
.group_by(
month=_.uploaded_on.truncate("M"),
ext=_.path.re_extract(r"\.([a-z0-9]+)$", 1)
.re_replace(r"cxx|cpp|cc|c|hpp|h", "C/C++")
.re_replace("^f.*$", "Fortran")
.replace("rs", "Rust")
.replace("go", "Go")
.replace("asm", "Assembly")
.nullif(""),
)
.aggregate(project_count=_.project_name.nunique())
.drop_null("ext")
.order_by([_.month.desc(), _.project_count.desc()])
)Data sources
PyPI dataset: Instructions for downloading the (large) dataset from Seth M. Larson