Ibis: an overview
2024-07-24
composable data systems
A Python perspective
“The Road to Composable Data Systems: Thoughts on the Last 15 Years and the Future” by Wes McKinney:
pandas solved many problems that database systems also solve, but almost no one in the data science ecosystem had the expertise to build a data frame library using database techniques. Eagerly-evaluated APIs (as opposed to “lazy” ones) make it more difficult to do efficient “query” planning and execution. Data interoperability with other systems is always going to be painful…
A Python perspective
“The Road to Composable Data Systems: Thoughts on the Last 15 Years and the Future” by Wes McKinney:
…unless faster, more efficient “standards” for interoperability are created.
Layers
“The Composable Codex” by Voltron Data:
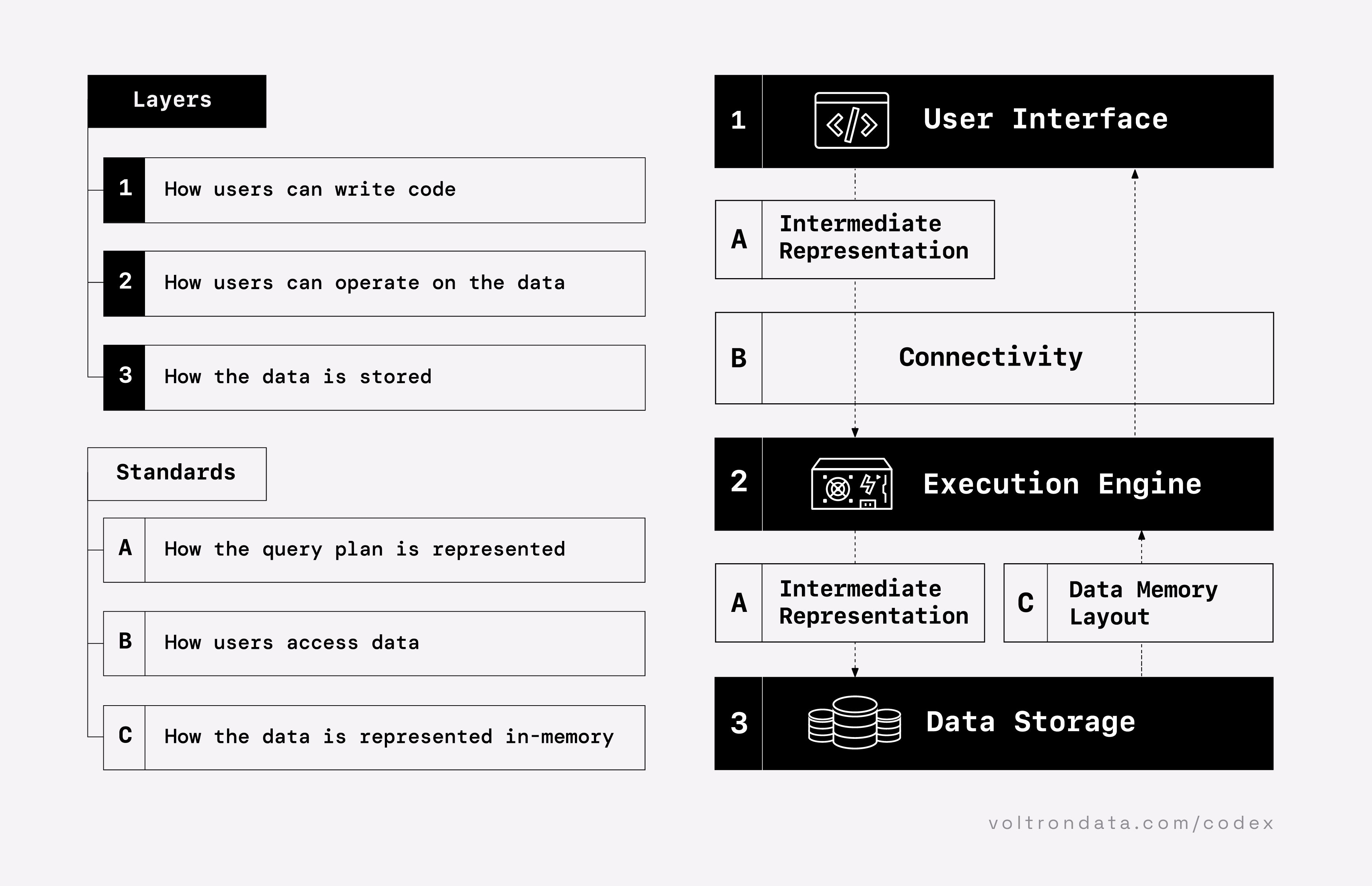
layers
Future
“The Composable Codex” by Voltron Data:
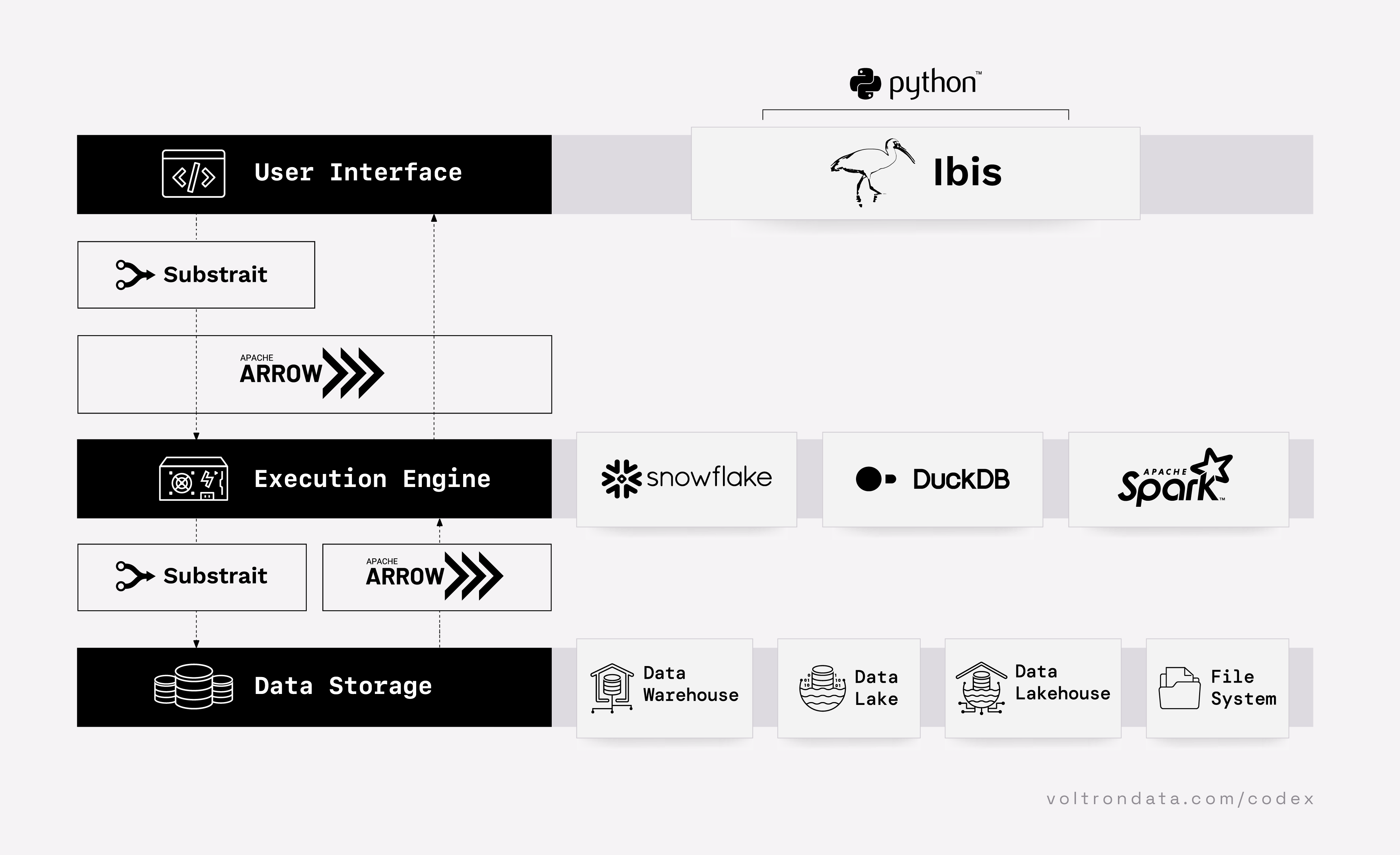
future
Why composable data systems?
Efficiency:
- time
- money
- data mesh
- engineering productivity
- avoid vendor lock-in
How can you implement it?
Choose your stack:
UI:
- Ibis (Python)
- dplyr (R)
- SQL
- …
Execution engine:
- DuckDB
- DataFusion
- Polars
- Spark
- Trino
- ClickHouse
- Snowflake
- Databricks
- Theseus
- …
Storage:
- Iceberg
- Delta Lake
- Hudi
- Hive-partitioned Parquet files
- …
Choose your stack (there’s more)
Additionally, choose tools for:
Orchestration:
- Airflow
- Prefect
- Dagster
- Kedro
- SQLMesh
- dbt
- …
Ingestion:
- dlt
- Airbyte
- requests
- Ibis
- …
Visualization:
- Altair
- plotnine
- Plotly
- seaborn
- matplotlib
- …
Dashboarding:
- Streamlit
- Quarto dashboards
- Shiny for Python
- Dash
- marimo
- …
Testing:
- Great Expectations
- Pandera
- Pytest
- assert statements
- …
CLI:
- Click
- Typer
- argparse
- …
what is Ibis?
Ibis is a Python library for:
- exploratory data analysis (EDA)
- analytics
- data engineering
- machine learning
- building your own library
- …
development to production with the same API
Getting started…
┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ bill_length_mm ┃ bill_depth_mm ┃ flipper_length_mm ┃ body_mass_g ┃ sex ┃ year ┃ ┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━┩ │ string │ string │ float64 │ float64 │ int64 │ int64 │ string │ int64 │ ├─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼───────┤ │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181 │ 3750 │ male │ 2007 │ │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186 │ 3800 │ female │ 2007 │ │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195 │ 3250 │ female │ 2007 │ └─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴───────┘
One API, 20+ backends
┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ bill_length_mm ┃ bill_depth_mm ┃ flipper_length_mm ┃ body_mass_g ┃ sex ┃ year ┃ ┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━┩ │ string │ string │ float64 │ float64 │ int64 │ int64 │ string │ int64 │ ├─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼───────┤ │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181 │ 3750 │ male │ 2007 │ │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186 │ 3800 │ female │ 2007 │ │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195 │ 3250 │ female │ 2007 │ └─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴───────┘
┏━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ count ┃ ┡━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━┩ │ string │ string │ int64 │ ├───────────┼───────────┼───────┤ │ Adelie │ Biscoe │ 44 │ │ Adelie │ Torgersen │ 52 │ │ Adelie │ Dream │ 56 │ │ Chinstrap │ Dream │ 68 │ │ Gentoo │ Biscoe │ 124 │ └───────────┴───────────┴───────┘
┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ bill_length_mm ┃ bill_depth_mm ┃ flipper_length_mm ┃ body_mass_g ┃ sex ┃ year ┃ ┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━┩ │ string │ string │ float64 │ float64 │ int64 │ int64 │ string │ int64 │ ├─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼───────┤ │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181 │ 3750 │ male │ 2007 │ │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186 │ 3800 │ female │ 2007 │ │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195 │ 3250 │ female │ 2007 │ └─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴───────┘
┏━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ count ┃ ┡━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━┩ │ string │ string │ int64 │ ├───────────┼───────────┼───────┤ │ Adelie │ Biscoe │ 44 │ │ Adelie │ Torgersen │ 52 │ │ Adelie │ Dream │ 56 │ │ Chinstrap │ Dream │ 68 │ │ Gentoo │ Biscoe │ 124 │ └───────────┴───────────┴───────┘
┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ bill_length_mm ┃ bill_depth_mm ┃ flipper_length_mm ┃ body_mass_g ┃ sex ┃ year ┃ ┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━┩ │ string │ string │ float64 │ float64 │ int64 │ int64 │ string │ int64 │ ├─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼───────┤ │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181 │ 3750 │ male │ 2007 │ │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186 │ 3800 │ female │ 2007 │ │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195 │ 3250 │ female │ 2007 │ └─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴───────┘
┏━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ count ┃ ┡━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━┩ │ string │ string │ int64 │ ├───────────┼───────────┼───────┤ │ Adelie │ Biscoe │ 44 │ │ Adelie │ Torgersen │ 52 │ │ Adelie │ Dream │ 56 │ │ Chinstrap │ Dream │ 68 │ │ Gentoo │ Biscoe │ 124 │ └───────────┴───────────┴───────┘
┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ bill_length_mm ┃ bill_depth_mm ┃ flipper_length_mm ┃ body_mass_g ┃ sex ┃ year ┃ ┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━┩ │ string │ string │ float64 │ float64 │ int64 │ int64 │ string │ int64 │ ├─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼───────┤ │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181 │ 3750 │ male │ 2007 │ │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186 │ 3800 │ female │ 2007 │ │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195 │ 3250 │ female │ 2007 │ └─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴───────┘
┏━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ count ┃ ┡━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━┩ │ string │ string │ int64 │ ├───────────┼───────────┼───────┤ │ Adelie │ Biscoe │ 44 │ │ Adelie │ Torgersen │ 52 │ │ Adelie │ Dream │ 56 │ │ Chinstrap │ Dream │ 68 │ │ Gentoo │ Biscoe │ 124 │ └───────────┴───────────┴───────┘
How it works
Ibis compiles down to SQL or dataframe code:
SQL + Python: better together
For SQL backends, inspect the SQL generated by Ibis:
SQL + Python: better together
For SQL backends, mix SQL and Python:
┏━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ count ┃ ┡━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━┩ │ string │ string │ int64 │ ├───────────┼───────────┼───────┤ │ Adelie │ Torgersen │ 52 │ │ Chinstrap │ Dream │ 68 │ │ Adelie │ Biscoe │ 44 │ │ Adelie │ Dream │ 56 │ │ Gentoo │ Biscoe │ 124 │ └───────────┴───────────┴───────┘
SQL + Python: better together
For SQL backends, mix SQL and Python:
┏━━━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ count ┃ ┡━━━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━┩ │ string │ string │ int64 │ ├───────────┼───────────┼───────┤ │ Gentoo │ Biscoe │ 124 │ │ Chinstrap │ Dream │ 68 │ │ Adelie │ Dream │ 56 │ │ Adelie │ Torgersen │ 52 │ │ Adelie │ Biscoe │ 44 │ └───────────┴───────────┴───────┘
demo
ibis-analytics
Analyzing 10M+ rows from 4+ data sources.
why
Dataframe lore
Dataframes first appeared in the S programming language (in 1991!), then evolved into the R programming language.
Then pandas perfected the dataframe in Python…or did it?
Since, dozens of Python dataframes libraries have come and gone…
The pandas API remains the de facto standard for dataframes in Python (alongside PySpark), but it doesn’t scale.
This leads to data scientists frequently “throwing their work over the wall” to data engineers and ML engineers.
But what if there were a new standard?
Ibis origins
from Apache Arrow and the “10 Things I Hate About pandas” by Wes McKinney
…in 2015, I started the Ibis project…to create a pandas-friendly deferred expression system for static analysis and compilation [of] these types of [query planned, multicore execution] operations. Since an efficient multithreaded in-memory engine for pandas was not available when I started Ibis, I instead focused on building compilers for SQL engines (Impala, PostgreSQL, SQLite), similar to the R dplyr package. Phillip Cloud from the pandas core team has been actively working on Ibis with me for quite a long time.
Two world problem
SQL:
Python:
Two world problem
SQL:
- databases & tables
Python:
- files & dataframes
Two world problem
SQL:
- databases & tables
- analytics
Python:
- files & dataframes
- data science
Two world problem
SQL:
- databases & tables
- analytics
- metrics
Python:
- files & dataframes
- data science
- statistics
Two world problem
SQL:
- databases & tables
- analytics
- metrics
- dashboards
Python:
- files & dataframes
- data science
- statistics
- notebooks
Two world problem
Python:
- files & dataframes
- data science
- statistics
- notebooks
SQL:
- databases & tables
- analytics
- metrics
- dashboards
Ibis bridges the gap.
Python dataframe history
- pandas (2008): dataframes in Python
- Spark (2009): distributed dataframes with PySpark
- Dask (2014): distributed pandas dataframes
- Vaex (2014): multicore dataframes in Python via C++
- Ibis (2015): backend-agnostic dataframes in Python
- cuDF (2017): pandas API on GPUs
- Modin (2018): pandas API on Ray/Dask
- Koalas (2019): pandas API on Spark, later renamed “pandas API on Spark”
- Polars (2020): multicore dataframes in Python via Rust
- Ibis (2022): Ibis invested in heavily by Voltron Data
- Snowpark Python (2022): PySpark-like dataframes on Snowflake
- Daft (2022): distributed dataframes in Python via Rust
- BigQuery DataFrames (2023): pandas API on Google BigQuery (via Ibis!)
- Snowpark pandas API (2024): pandas API on Snowflake
- SQLFrame (2024): backend-agnostic dataframes in Python (PySpark API)
- DataFusion dataframes (2024): multicore dataframes in Python via Rust
Obligatory standards xkcd

standards
Standards and composability
All Python dataframe libraries that are not Ibis (or SQLFrame) lock you into an execution engine.
Good standards are composable and adopted by competitors.
Python dataframe history (aside)
We see three approaches:
pandas clones:
- Modin
- pandas API on Spark
- formerly known as Koalas
- cuDF
- Dask (sort of)
- BigQuery DataFrames
- Snowpark pandas API
PySpark clones:
- SQLFrame
- Snowpark Python (sort of)
- DuckDB Spark API
- SQLGlot Spark API
something else:
- Ibis
- Polars
- Daft
- DataFusion
Database history
- they got faster
Ibis brings the best of databases to dataframes.
DuckDB
An embeddable, zero-dependency, C++ SQL database engine.
DataFusion
A Rust SQL query engine.
ClickHouse
A C++ column-oriented database management system.
Polars
A Rust DataFrame library.
BigQuery
A serverless, highly scalable, and cost-effective cloud data warehouse.
Snowflake
A cloud data platform.
Oracle
A relational database management system.
Spark
A unified analytics engine for large-scale data processing.
Trino
A distributed SQL query engine.
…and more!
- SQLite
- PostgreSQL
- MySQL
- MSSQL
- Druid
- pandas
- Impala
- Dask
New backends are easy to add!*
*usually
how
Try it out now!
Install:
Then run:
┏━━━━━━━━━┳━━━━━━━━━━━┳━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━┳━━━━━━━━┳━━━━━━━┓ ┃ species ┃ island ┃ bill_length_mm ┃ bill_depth_mm ┃ flipper_length_mm ┃ body_mass_g ┃ sex ┃ year ┃ ┡━━━━━━━━━╇━━━━━━━━━━━╇━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━╇━━━━━━━━╇━━━━━━━┩ │ string │ string │ float64 │ float64 │ int64 │ int64 │ string │ int64 │ ├─────────┼───────────┼────────────────┼───────────────┼───────────────────┼─────────────┼────────┼───────┤ │ Adelie │ Torgersen │ 39.1 │ 18.7 │ 181 │ 3750 │ male │ 2007 │ │ Adelie │ Torgersen │ 39.5 │ 17.4 │ 186 │ 3800 │ female │ 2007 │ │ Adelie │ Torgersen │ 40.3 │ 18.0 │ 195 │ 3250 │ female │ 2007 │ │ Adelie │ Torgersen │ NULL │ NULL │ NULL │ NULL │ NULL │ 2007 │ │ Adelie │ Torgersen │ 36.7 │ 19.3 │ 193 │ 3450 │ female │ 2007 │ │ Adelie │ Torgersen │ 39.3 │ 20.6 │ 190 │ 3650 │ male │ 2007 │ │ Adelie │ Torgersen │ 38.9 │ 17.8 │ 181 │ 3625 │ female │ 2007 │ │ Adelie │ Torgersen │ 39.2 │ 19.6 │ 195 │ 4675 │ male │ 2007 │ │ Adelie │ Torgersen │ 34.1 │ 18.1 │ 193 │ 3475 │ NULL │ 2007 │ │ Adelie │ Torgersen │ 42.0 │ 20.2 │ 190 │ 4250 │ NULL │ 2007 │ │ … │ … │ … │ … │ … │ … │ … │ … │ └─────────┴───────────┴────────────────┴───────────────┴───────────────────┴─────────────┴────────┴───────┘